
This blog post by Joe Nockels explores the creation of the first Library dataset to be generated using the Artificial Intelligence (AI) technology of Handwritten Text Recognition (HTR). As a result we now have an accurate semi-automatic transcription of the diaries of Scottish child author Marjory Fleming (1803-1811).
Few historical texts voice the experience of children in their own words. Marjory Fleming’s famous diary, presented to the National Library of Scotland in 1930, is a rare exception. The pages are filled with witticisms, moralisms and copybook notes, all completed under the watchful gaze of Fleming’s tutor and older cousin Isabella Keith.
Incidentally, Keith’s corrections can be seen throughout the diary – something which, surprisingly, does little to make it any less personal. Written mainly in Edinburgh and her holiday retreats of Ravelston and Braehead, the diary simultaneously serves as the authoritative record of the young writer’s life as well as a textbook of sorts.
The collection ends with a few pages written not in Fleming’s hand but those of Isabella Keith and Fleming’s mother, Isabella. They express their deep grief in Marjory’s untimely death at the age of 8, in December 1811, from measles and meningitis. In their words, Marjory was left powerless to act against ‘… so heavenly mercy’s plan …’
Marjory’s status as a child genius was soon entrenched. John Brown’s glowing essay of 1863 described her as ‘bright, eager child …’; and subsequently other writers expressed similar affections, notably Robert Louis Stevenson, Mark Twain and Leslie Stephen. Fleming’s distant relation to Walter Scott became exaggerated in the process, with Brown suggesting that Scott believed her to be ‘the most extraordinary creature’ he ever met. Genius or not, the precociousness and free-thinking shown in her diary entries offers significant insights into early 19th-century Scotland. Could we make these insights accessible to a wider audience? That was my challenge.
Digitisation enables a library to make a copy of a manuscript widely (and remotely) available. However, the question ‘Is there also a transcription?’ always follows! Traditionally transcriptions help by providing an accurate version of the text to be used in conjunction with the original or its surrogate; but, increasingly, they can drive digital scholarship activities and support the ‘Collections As Data’ philosophy.
If a transcription – no longer just considered as a more easily readable copy of the original – can be broken down into fundamental elements of letters, words, lines, etc., there are more opportunities to use computational methods to analyse and interpret the text. Creating accurate transcriptions has always been a time-consuming human activity, but advances in Artificial Intelligence have seen the development of powerful tools now able to undertake much of that work. Transkribus, a Handwritten Text Recognition (HTR) platform, is one such tool and it was this platform that I used to create automatic transcriptions of the Fleming diary. Technically, Transkribus uses AI and predictive language patterns to decipher historical handwriting, but to be able to use Transkribus, you don’t have to understand the cleverness behind it. Using the platform, you follow a basic and well-documented process.
I started with scanned images of the diary (available through the Library’s Digital Gallery). Images were uploaded to Transkribus and each scan, representing a folio of the original, was analysed using the Layout Analysis (LA) feature, which assesses the structure of the foilo, identifying and segmenting specific features which the HTR model can be trained against.
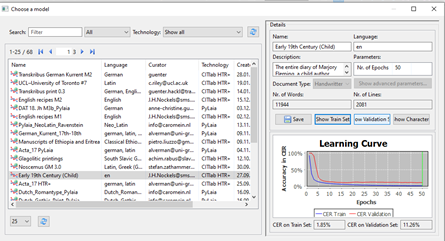
I then had to create an HTR model of Marjory’s handwriting, starting with transcribing a percentage of the work manually as the HTR model needs some initial help. There are a recommended number of words to train the model (15000) but if a relatively short manuscript like Fleming’s is being transcribed, the model can be trained with fewer words.
Even with fewer than recommended words, the Fleming model I created produced a very low (1.85%) character recognition error rate. These manual transcriptions, the training set, were then compared against an unworked validation set. With each revision of the training set the HTR model checked it against the validation set to demonstrate progress.
Transkribus interpreted Marjory’s hand with impressive speed. Training the model takes time but is fundamental to the success of the transcription. When the HTR model for Marjory’s handwriting was ready the resulting transcription was presented in a separate text editor with each line of text in the editor matching the same line in the digitised image. An advantage of the model (shown below) is that it is reusable, can be saved within Transkribus, and further made available to others as a base model for similar works.
As well as HTR transcription the platform also allows particular elements of transcription text to be marked for use in later interpretation and re-use, e.g. personal and place names, such as mentions of Fleming’s tutor or the town of Kirkcaldy, as well as structural text elements like strikethroughs and superscript.
After transcriptions have been created they can be exported in multiple formats, including highlighted PDFs and ALTO files. Working with Dr Sarah Ames, the Library’s Digital Scholarship Librarian, we prepared an export of the Fleming dataset for the Library’s Data Foundry.
This work on the Fleming diary has shown the effectiveness of HTR in a particular context, but my continuing research also aims to consider how such technologies might be incorporated into the workflows of institutions like the Library, who else may benefit from these transcriptions and how they might be used. Transkribus has been explained here, but I am also generally monitoring and reviewing developments in HTR technology and will assess other options as they become available or more established. The use of AI in archives holds many opportunities for exploration and has much potential.
Joe Nockels, AHRC funded PhD student, via the Scottish Graduate School for Arts & Humanities.